Em nossas conversas com gestores e consultores que atendemos aqui na DataSpoc, um desafio se repete: como transformar dados desorganizados em respostas rápidas que geram impacto, sem sobrecarregar equipes já enxutas? A resposta está em processos automáticos conhecidos como data pipelines.
O que é data pipeline?
Data pipeline, em tradução livre, é um fluxo automatizado para coletar, transformar e entregar dados com segurança e velocidade para as pessoas certas. Imagine um encanamento invisível que transporta as informações de diferentes fontes até chegar prontinho à mesa da decisão, sem parar no meio do caminho.
Dados não organizados viram perguntas sem resposta.
Um data pipeline ajuda pequenas empresas a ganhar tempo, reduzir retrabalho e criar rotinas confiáveis para usar seus dados no dia a dia. Sem processos como esse, planilhas se multiplicam, as versões se confundem e a confiança nos relatórios diminui.
Por que pequenas empresas devem investir em data pipelines?
Muitos pensam que soluções assim são restritas a grandes empresas ou gigantes da tecnologia. Mas, em nossa experiência, clientes de todos os portes colhem resultados reais com esse passo:
- Redução do tempo gasto com tarefas manuais na consolidação de dados;
- Facilidade para encontrar informações corretas na hora da decisão;
- Maior confiança nos indicadores, já que se elimina a manipulação manual;
- Escalabilidade: se a empresa crescer, o fluxo acompanha sem dores de cabeça.
Esse tipo de automação libera o time para pensar no negócio, não só em juntar arquivos. Tem relação direta com temas como automação empresarial e escalabilidade.
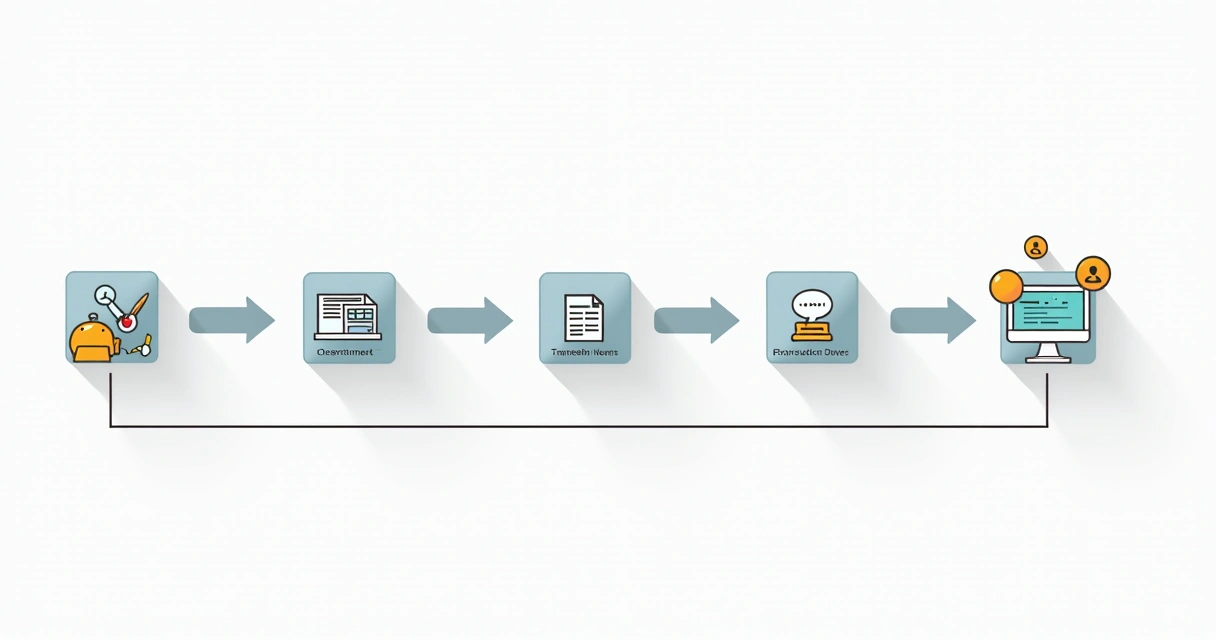
Principais etapas de um data pipeline
O pipeline costuma seguir algumas etapas principais, que podem ser adaptadas à realidade de cada empresa:
- Coleta dos dados: Buscamos dados em várias fontes: planilhas, ERPs, CRMs ou bancos de dados.
- Limpeza e transformação: Corrigimos erros, removemos duplicidades, padronizamos campos e deixamos tudo pronto para análise.
- Armazenamento intermediário: Guardamos os dados tratados em um local seguro, como um banco de dados ou arquivo centralizado.
- Entrega ou visualização: Levamos o dado pronto ao usuário, seja via dashboard, relatório ou integração com outro sistema.
- Monitoramento e manutenção: Checamos se tudo corre como previsto, com alertas para falhas ou atrasos na atualização.
Essas etapas podem parecer técnicas, mas se transformam em rotinas fáceis com as ferramentas certas. O segredo está em não complicar o que pode ser simples.
Quais tecnologias usar para pipelines acessíveis?
Não faltam opções no mercado. Mas, na hora de colocar em prática, é possível começar com ferramentas conhecidas e de fácil adoção:
- Planilhas do Google com scripts automatizados (Apps Script);
- Power Query no Excel para transformação de dados com poucos cliques;
- Ferramentas de integração como Zapier ou Make combinando sistemas sem programação;
- Bancos de dados simples (MySQL, SQLite, PostgreSQL);
- Dashboards em Google Data Studio, Power BI ou Looker Studio.
Escolher tecnologias fáceis de manter é parte essencial do sucesso em pequenas equipes. Não precisa começar do zero: muitas funções são acessíveis mesmo com pouca familiaridade técnica. Sempre indicamos avaliar o conhecimento prévio do time na escolha do que adotar.
Dicas para vencer barreiras técnicas e culturais
Sabemos que não basta a tecnologia funcionar: é preciso que as pessoas aceitem e usem o novo fluxo na rotina. Algumas recomendações práticas do nosso time:
- Envolva a equipe cedo, ouvindo sobre dores e sugerindo melhorias;
- Mostre ganhos rápidos, como relatórios saindo em minutos onde antes levavam dias;
- Documente o que mudou, garantindo transparência e treinamento acessível;
- Designe alguém como responsável pelo pipeline, mesmo que em tempo parcial;
- Monitore e celebre pequenos avanços. Pequenas vitórias criam cultura de dados.
É natural surgir medo de perder o controle ou de tornar o fluxo complicado demais. Nossa experiência mostra o contrário: quando o pipeline é bem desenhado, vira aliado. E, claro, ao contar com apoio de especialistas como oferecemos na DataSpoc, a jornada fica muito mais leve, mesmo em pequenos negócios.
Soluções simples, continuadas e adaptadas ao contexto geram engajamento.
Benefícios reais para consultores e gestores
Para o consultor de gestão, pipelines de dados trazem agilidade e precisão aos projetos. Vamos a exemplos que costumamos vivenciar ao implementar essas soluções:
- Consultores economizam tempo ao não precisar consolidar dados manualmente de várias fontes dos clientes;
- Decisões ganham respaldo em relatórios confiáveis, alimentados automaticamente e sempre atualizados;
- Permanecer focado na análise crítica, sem se perder em tarefas operacionais;
- Criar cultura data-driven sem depender de grandes investimentos ou estrutura robusta;
- Sensação de entrega engajada: consultor vira parceiro do sucesso, não fornecedor pontual.
Temos visto que muitos consultores conseguem ampliar o portfólio e entregar valor recorrente quando dominam esses fluxos de dados. Isso está diretamente ligado ao conceito de gestão orientada a dados.

Como iniciar um pipeline de dados sem drama?
Nossa recomendação sempre parte do concreto: identifique ao menos um KPI crítico para a operação. Reúna os dados já existentes, mesmo que estejam dispersos em planilhas e sistemas distintos, e pense como seria o fluxo ideal para entregar essa informação atualizada a quem toma a decisão.
A seguir, sugerimos prototipar antes de investir em grandes integrações. Ferramentas como as citadas anteriormente ajudam muito nesse começo, inclusive via automações que demandam pouco código ou conhecimento de TI. Sempre que necessário, lembre que parceiros como a DataSpoc atuam do desenho à sustentação, nossos clientes aprovam a ideia de ter valor entregue em 30 dias e monitoramento contínuo.
Evite armadilhas: erros comuns ao criar data pipelines
Todo projeto pode encontrar tropeços, mas conhecendo os principais riscos, é fácil desviar:
- Tentar resolver tudo de uma vez, sem priorizar as entregas mais relevantes;
- Escolher tecnologias muito avançadas para o perfil do time;
- Não treinar as pessoas e criar dependência excessiva de uma única pessoa;
- Ignorar monitoramento ou não estabelecer processos para atualização;
- Deixar dados sensíveis expostos, sem atenção à segurança.
Foco na simplicidade e clareza desde o início é o melhor caminho para pipelines que dão certo.
Acompanhar conteúdos sobre operações e inovação em transformação digital também ajuda a estimular novas ideias ajustadas ao contexto de pequenas empresas.
Conclusão
Adotar data pipelines não é só para os grandes players. Ao contrário! Pequenas empresas podem dar saltos de qualidade, confiança e velocidade ao trabalhar seus dados de forma simples e lógica. Em nossa trajetória na DataSpoc, já vimos times tomando decisões melhores porque escolheram estruturar e automatizar seus fluxos, mesmo sem grandes investimentos em TI.
Caso queira transformar seus dados em resultados concretos, automatizar relatórios ou prototipar soluções com inteligência artificial operacional, conheça nossos serviços e vamos conversar sobre como criar ou turbinar seu data pipeline.
Perguntas frequentes sobre data pipelines em pequenas empresas
O que é um data pipeline?
Um data pipeline é um fluxo automatizado de etapas que coleta, limpa, transforma, armazena e entrega dados prontos para análise e decisão. Ele conecta as fontes de dados ao resultado, tornando as informações confiáveis e fáceis de acessar.
Como implementar um data pipeline simples?
Comece definindo um objetivo claro (por exemplo, gerar um relatório de vendas atualizado) e liste as fontes de dados (planilhas, sistema de vendas, etc). Use ferramentas acessíveis, como Google Planilhas com automações ou Power BI, para juntar, tratar e visualizar as informações. Prototipe antes de investir e envolva a equipe desde o início.
Vale a pena usar data pipeline em pequenas empresas?
Sim! Mesmo negócios de pequeno porte ganham tempo, confiança e capacidade de crescimento ao automatizar o fluxo de dados. O investimento inicial costuma ser baixo quando se começa de forma simples, e os ganhos superam os custos em poucas semanas.
Quais são as etapas de um data pipeline?
As etapas mais comuns são: coleta de dados, limpeza e transformação, armazenamento intermediário, entrega dos dados ao usuário, além do monitoramento para garantir que tudo funcione no tempo certo. Ajustamos essas etapas conforme a realidade de cada negócio.
Quanto custa montar um data pipeline?
O custo depende da complexidade e das tecnologias escolhidas. É possível iniciar com ferramentas gratuitas ou de baixo custo, priorizando as demandas mais frequentes. Projetos completos, como entregamos na DataSpoc, variam de acordo com o volume de dados, integrações e necessidades de monitoramento, mas sempre buscamos soluções sob medida para o orçamento disponível.